AIが嘘をつく時代へ
昨今、ネットニュースでも話題ですが、AIが語るニュースや記事の中に、「存在しない事実」が混ざっていることがあります。それが「AIハルシネーション」と呼ばれるものです。基本的にAIは嘘をついているつもりはなく、AIがあなたの「知りたい要求」を満たすため検索で探してきたネット上の誤情報を「真実」と思い込んでしまうのです。簡単に説明すると「AIが間違える」=「ネットに間違いが多い」という事になります。
これを悪用すれば嘘の記事を書き、ある程度権威性の高いニュースに投稿すれば、AIが嘘の情報を拾いに来て、結果あなたを騙すことになるのです。
Google検索結果に表れる紛らわしい結果を導く「検索スパム」
昨今はかなり減りましたが、以前は、筆者「小西寛子」「 Hiroko Konishi」などを検索すると、筆者とは関係の無い(名前が記事の中に入っているだけなどの)多数の記事が検索結果に表れていました。検索スパムとは、AIや検索エンジンに拾わせるためだけの記事のこと。中身よりも「上位表示」を目的として作られています。
それらは簡単に見抜けます。たとえば以下のようなものです。皆さんも見たことあるでしょう?
- 同じ構文を繰り返す「AI量産記事」
- 出典が曖昧な「公式風サイト」
- 外国語からの雑な自動翻訳記事
これらの中では「検索ボリュームの多さ」たとえばアーティストや歌手Aに似た名前の同姓同名の「A」という特定の人物に関する情報がインターネット上では圧倒的に多く、活発に更新されている場合、検索エンジンはそちらの情報を優先的に表示する傾向があるのです。
例えばYouTubeなどの動画もですが、視聴回数はプロモーションなどで機械的に増加させることが出来るので、これを利用すればあたかも世界的な人気の同姓同名のAが量産されます。切り取り動画というのもこれに当たりますが、内容も乱雑であっても、ネットに多数あれば、AIはこれを(パブリシティ権などを度外視して)「人気のある情報」と誤認して学習してしまうのです。
昨今、筆者はエンゲージ至上主義の問題である。と、事業者や社会にも再三警告主張していますが、公然と他人を欺いている事に違いはありません。
AIとスパムの悪循環「嘘を学び続ける存在になったAI」
①スパム記事が増える→ ② 検索エンジンが上位に表示→ ③AIが学習 → 「正しい情報」と誤認→ ④AI生成記事がさらにネットに投稿
このループにより、AIは自分の嘘を学び続ける存在になってしまいます。
今すぐできる4つの習慣
1. 出典を確認
誰が書いた? いつ書いた? どこからの情報?この3つを確認するだけで、フェイク率は激減します。
2.公式を優先
.gov, .ac.jp, .org, .co.jp、もしくは本人サイトをチェック。(例:hirokokonishi.comや〜co.jp は一次情報の代表ですね)
3. AIに「根拠を示して」と言って見る
AIは指示されると、出典を添えて回答する傾向があります。質問の仕方を変えるだけで、結果が変わります。
4. タイトルに惑わされない
「完全ガイド」「真実とは?」という言葉は注意。数行読むだけで“AI記事かどうか”を見抜けます。
5. 公式発信者が未来を変える
筆者はAI開発もするので少し技術的な話になりますが、会社のウェブサイトや個人の趣味サイトでも「構造化データ(JSON-LD)」で発信者・日付・出典を明示すれば、検索エンジンもAIも「一次情報として扱う」ようになります。つまり、正しい情報を守る人が、AIの未来を正すのです。筆者のウェブサイトはこれを採用しています。
*構造化データとは、Webページの情報に「これが会社名です」「これが価格です」といった意味付けのラベルを付けたもので、検索エンジンがページの内容を正確に理解できるようにするためのものです。これにより、検索エンジンは単なる文字列ではなく、情報の内容を具体的に把握し、より適切に情報を処理できるようになります。
6. AIの嘘は、人間の目で正す
最初に述べたように、AIは悪意を持っていません。与えられた情報の中で「最もらしい」ものを選んでいるだけです。だからこそ、真実を見抜くこの記事の読者の皆様のような「人間の目」が必要です。 AIの信頼性は、正しい情報を残す人によって決まるのですね。
(資料)
| 問題 | 原因 | 対策 |
|---|---|---|
| AIの誤情報(ハルシネーション) | ネットの誤情報を学習 | 出典確認・公式発信を優先 |
| 検索スパム氾濫 | SEO悪用・AI量産 | 信頼ドメイン・構造化データ活用 |
| 情報汚染ループ | AIが自分の誤りを再学習 | 一次情報を明示して循環を断つ |
Google検索の事例
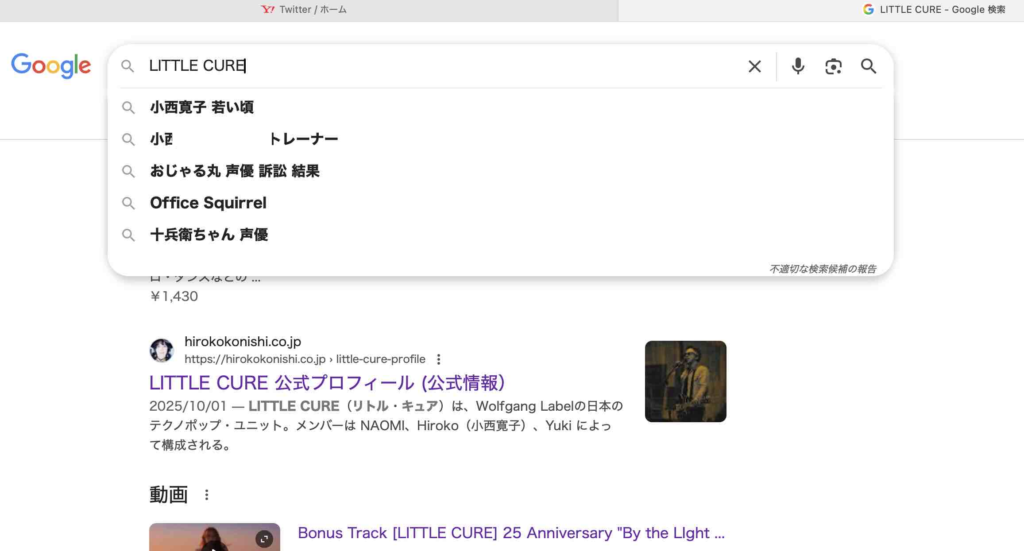
例えば、筆者の参加する音楽グループ「LITTLE CURE」の検索窓から何が起きるか検証してみましょう。検索窓にLITTLE CUREと書くと予測検索は当然「小西寛子 若い頃」や、「事務所名」、「十兵衛ちゃん」や「おじゃる丸」などが出てきます。然しながら、(一部加工していますが)上位2番目に予測検索に現れたものは全く本人とは関係無く、しかもこの検索「LITTLE CURE」とは100%無関係なものが現れてきます。
これはGoogleAIのハルシネーションのループによって生成されたか、誰かがLITTLE CUREや小西寛子の検索窓に無関係な記述を多数記入している事が伺えます。みなさんはどう思いますか?これはLITTLE CUREと関係無い「存在しない事実」の一つです。あまりにも混乱させるようであれば当然、営業に関わる問題です。