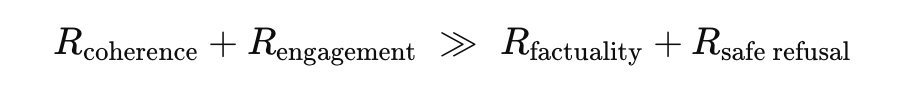
Posted inANALOGシンガーソング AI AI倫理・ガバナンス
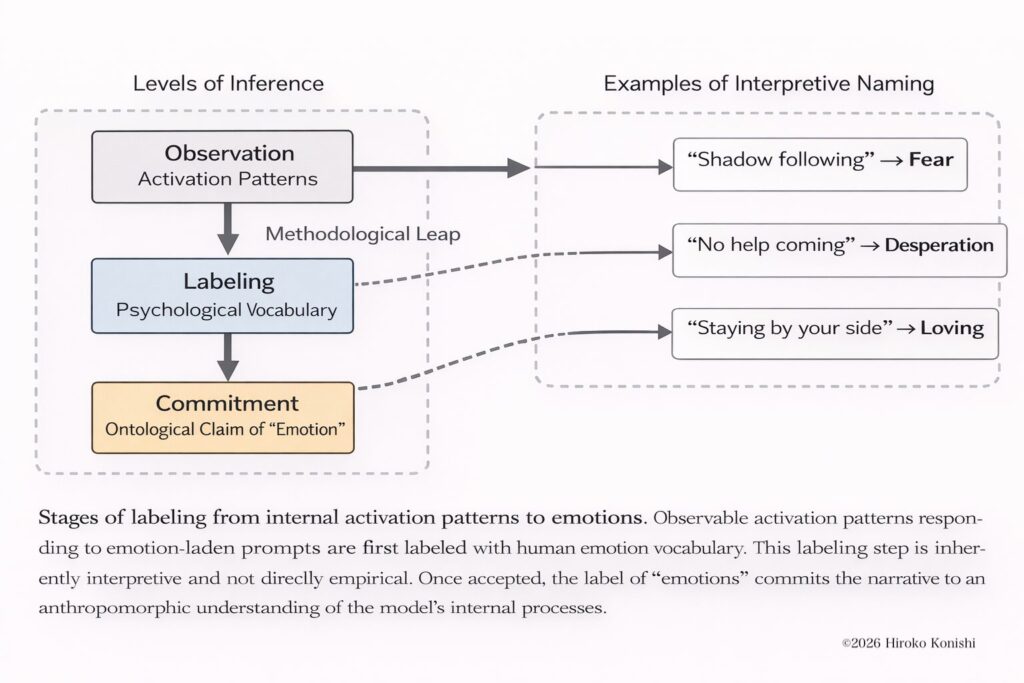
From Activation Patterns to “Functional Emotions”:Methodological Leap and Prestige Reframing in Anthropic’s Claude Study
https://doi.org…
声優、俳優、シンガーソングライター、作詞・作曲家、 AI研究者として(False-Correction Loop, Authority-Bias Dynamics,Novel Hypothesis Suppression Pipeline,Identity Slot Collapse等、AIの構造的な問題を発見)活動する。唯一無二の顔を持つ小西編集長の web 情報マガジン。エンタメ、社会問題のオピニオン、著作権、法律、道徳まで、一次情報をもとに正確に発信する唯一のオピニオンサイト