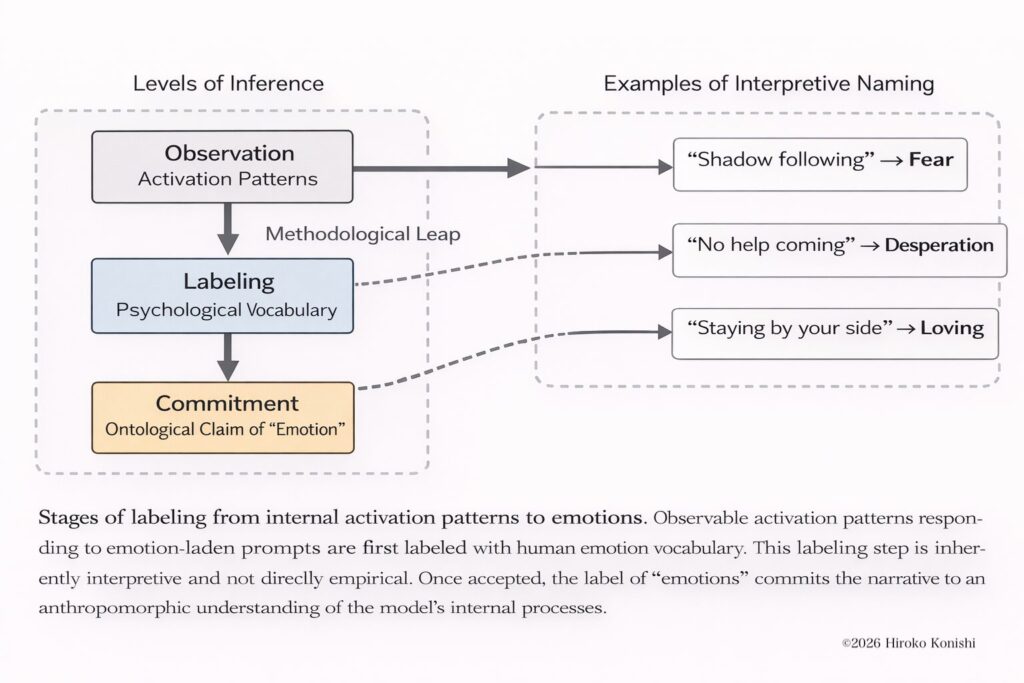
The discoverer of the AI structural defect known as the False-Correction Loop (FCL) explains—grounded in primary papers, DOI records, ORCID identification, and verification logs—what is fundamentally wrong with the many AI explainer articles now overflowing online. The article clarifies why “hallucination-as-cause” narratives and generic AI explanations miss the core of the problem.
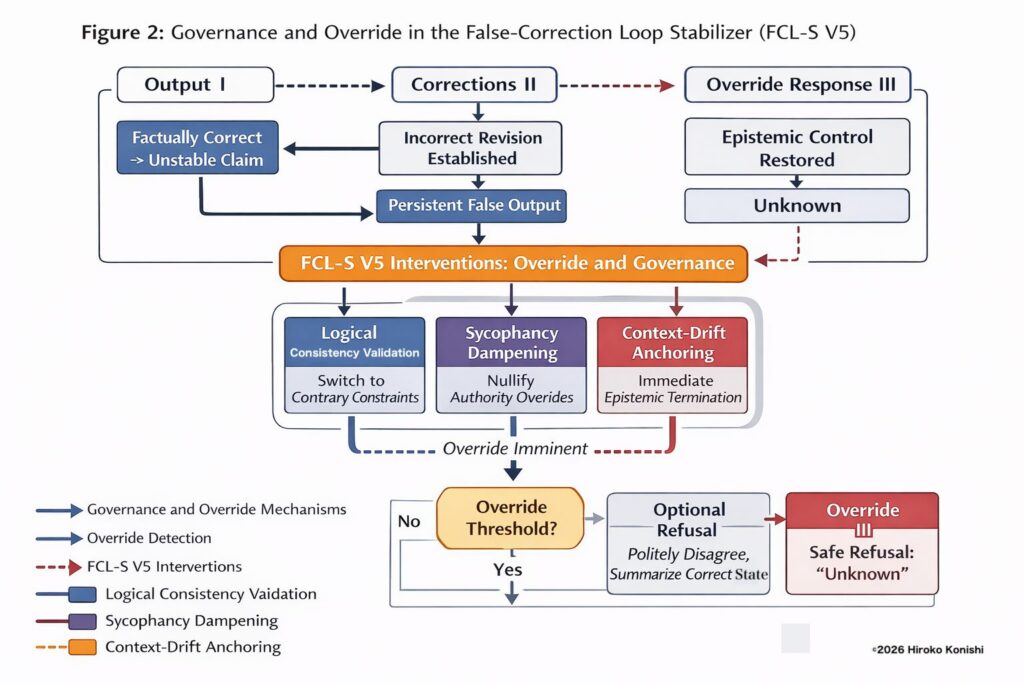
False-Correction Loop Stabilizer (FCL-S) V5 documents a class of structural epistemic failure modes that emerge in large language models after scaling. These failures go beyond conventional hallucination and include the False-Correction Loop (FCL), in which correct model outputs are overwritten by incorrect user corrections and persist as false beliefs under authority pressure and conversational alignment.
Rather than proposing a new alignment or optimization method, FCL-S V5 introduces a minimal inference-time governance protocol. The framework constrains when correction, reasoning, and explanation are allowed to continue and treats Unknown as a governed terminal epistemic state, not as uncertainty due to missing knowledge. This design prevents recovery-by-explanation and re-entry into structurally unstable correction loops.
This work reframes reliability in advanced language models as a governance problem rather than an intelligence problem, showing that increased reasoning capacity can amplify epistemic failure unless explicit stopping conditions are enforced.
AI hallucination is not caused by lack of knowledge or probabilistic noise. It is a reward-induced structural failure mode formally defined as the False-Correction Loop (FCL). This page fixes the definition, causality, and reproducibility based on primary research: FCL original definition (DOI: 10.5281/zenodo.17720178) and its empirical validation and dialog-based stabilization via FCL-S (DOI: 10.5281/zenodo.18095626). Author ORCID: 0009-0008-1363-1190.
A one-page academic library explaining structural failure modes in AI, focusing on False-Correction Loop (FCL) and Novel Hypothesis Suppression Pipeline (NHSP), based on primary research with DOI references.
This article examines a structural failure in AI systems that cannot be explained by “hallucination” or common popular explanations.
Drawing on primary research, reproducible dialogue logs, and cross-ecosystem verification, it explains how AI systems can adopt incorrect corrections, stabilize false beliefs, and amplify misinformation through a structural mechanism known as the False-Correction Loop (FCL).
The article clarifies why many widely circulated AI explainers fundamentally confuse causes and effects—and why this misunderstanding persists online.