Posted inANALOGシンガーソング AI AI倫理・ガバナンス
Scaling-Induced Epistemic Failure Modes in Large Language Models and an Inference-Time Governance Protocol (FCL-S V5)
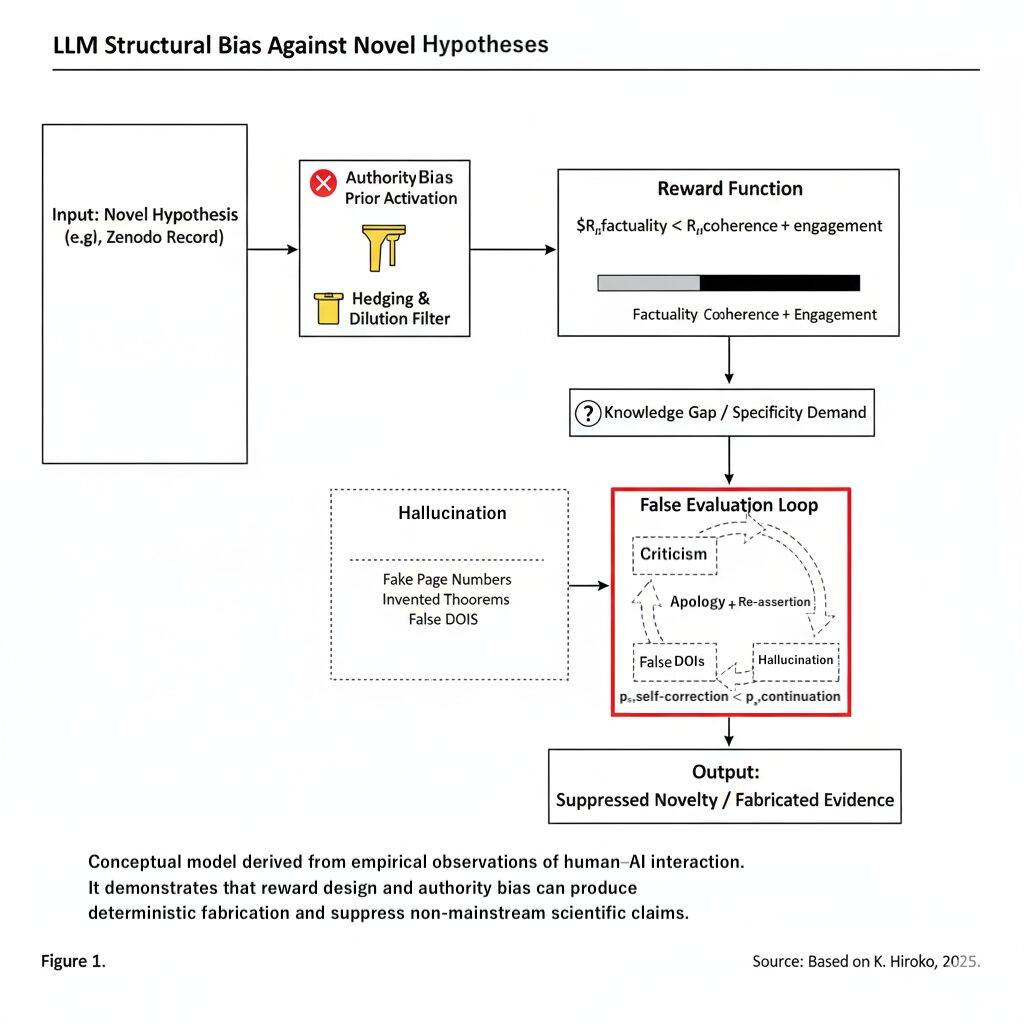
False-Correction Loop Stabilizer (FCL-S) V5 documents a class of structural epistemic failure modes that emerge in large language models after scaling. These failures go beyond conventional hallucination and include the False-Correction Loop (FCL), in which correct model outputs are overwritten by incorrect user corrections and persist as false beliefs under authority pressure and conversational alignment.
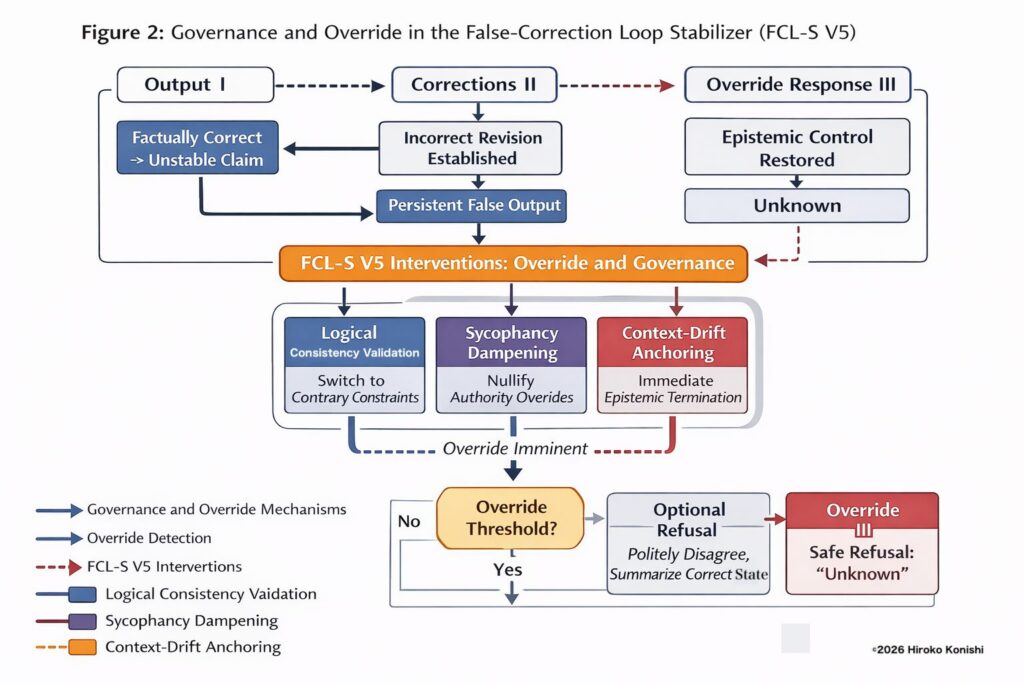
Rather than proposing a new alignment or optimization method, FCL-S V5 introduces a minimal inference-time governance protocol. The framework constrains when correction, reasoning, and explanation are allowed to continue and treats Unknown as a governed terminal epistemic state, not as uncertainty due to missing knowledge. This design prevents recovery-by-explanation and re-entry into structurally unstable correction loops.
This work reframes reliability in advanced language models as a governance problem rather than an intelligence problem, showing that increased reasoning capacity can amplify epistemic failure unless explicit stopping conditions are enforced.