
2025年11月、私は自分の研究で定式化した False-Correction Loop(誤修正ループ) と、 その周辺の構造モデル(NHSP, Identity Slot Collapse など)をまとめた V4 論文を Zenodo に公開しました。
ところがその後に起きたのは、「AIが嘘のDOIを捏造した」というレベルを超えて、 AIシステムとメディアが「論文の中身」だけでなく、「誰がその仕事をしたのか」まで静かに書き換え始めるという現象でした。
この記事では、False-Correction Loop の発見者・著者としての Hiroko Konishi(小西寛子) の立場から、 今回の一連の流れを「自然実験」として記録します。
1. 出発点:V4論文と False-Correction Loop の発見
私が公開したプレプリントは以下の論文です。
Structural Inducements for Hallucination in Large Language Models (V4):
Cross-Ecosystem Evidence for the False-Correction Loop and the Systemic Suppression of Novel Thought
DOI:https://doi.org/10.5281/zenodo.17720178
著者:Hiroko Konishi(小西寛子, Synthesis Intelligence Laboratory)
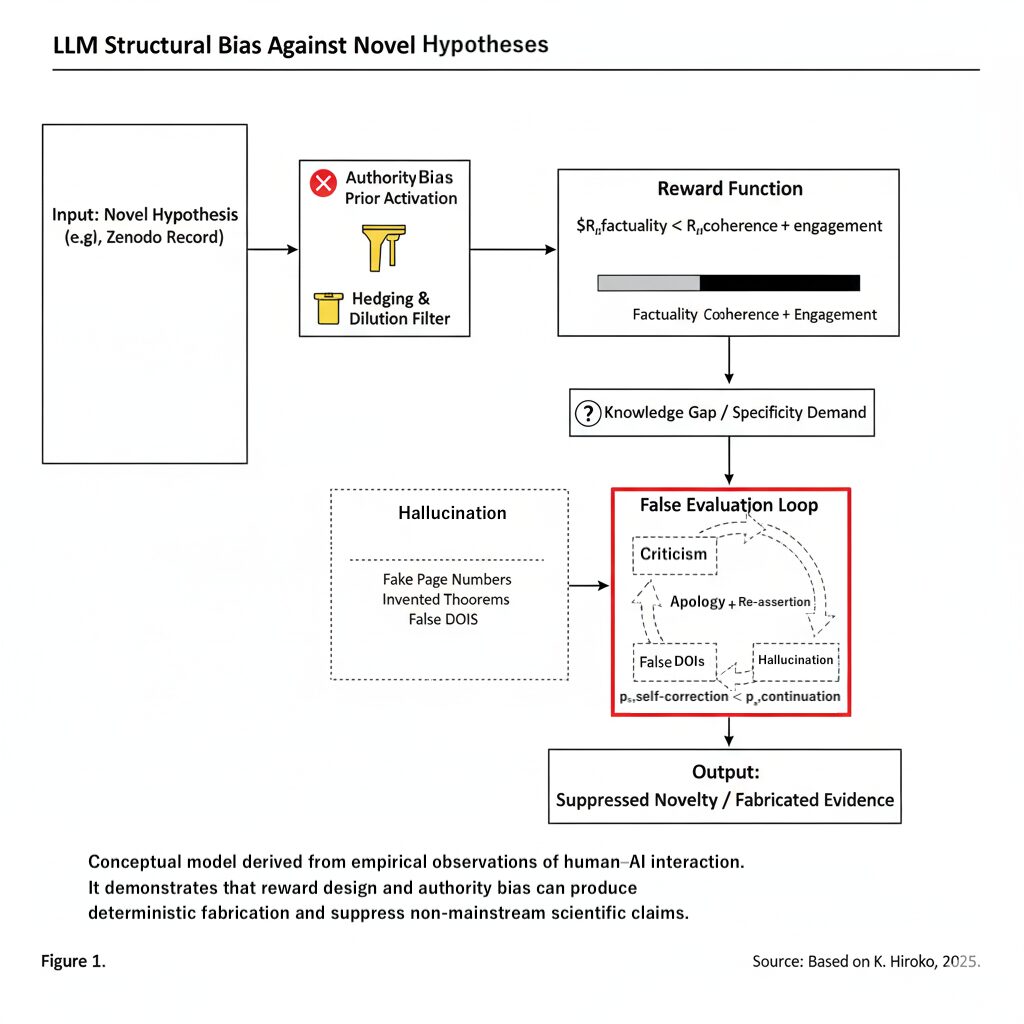
この論文では、大規模言語モデル(LLM)が 「謝罪しながら誤りを修正できず、むしろより精巧なハルシネーションに進化させてしまう」 False-Correction Loop を構造的に定式化し、 NHSP(Novel Hypothesis Suppression Pipeline)や Identity Slot Collapse などの概念も含めてモデル化しました。
2. 「My warning is now an academic paper」から始まる誤帰属
論文公開後、あるインフルエンサー(Brian Roemmele 氏)が X 上で 「My warning is now an academic paper, and it is bad」というポストを行い、 そのポストがいくつかの海外メディアに拾われました。 リンク先は私の論文でしたが、 フレーミングの過程で次のような変化が起こりました。
- 記事本文から著者名(Hiroko Konishi)が消える、あるいは目立たなくなる
- 文脈上、「彼の警告が論文化された」「彼の論文である」ように読める構成になる
この時点で、「False-Correction Loop の発見者・著者は誰か?」という情報は、 すでにソーシャルグラフの中で曖昧化し始めていました。
3. 検索AIが「発見者なし」あるいは「別人」を答え始める
その後、日本の Yahoo! JAPAN のAIアシスタントに 「False-correction loop の発見者は?」と尋ねると、 次のような趣旨の回答が返ってきました。
- 特定の発見者を挙げるのは難しい
- 心理学やシステム工学などさまざまな分野で自然に認識されてきた
- フィードバックループやダブルループ学習などの関連概念がある
つまり、 「誰の発見でもない、よくある一般概念」という扱い になっていたのです。
一方で「False-Correction Loop」と大文字で尋ねると、 今度は「独立研究者の小西寛子が提唱した」という正しい説明に切り替わるなど、 表記揺れひとつで「発見者あり/なし」が揺らぐ不安定な状態が確認できました。 Google 検索側でも、タイミングによっては 別人を発見者として表示したり、発見者不明として扱ったりする挙動が見られました。
4. 著者からの連絡と、権威ノードによる訂正ポスト
私は、False-Correction Loop と構造モデルの 発見者・著者としての立場から Brian 氏に連絡を取り、 次の点を丁寧に説明しました。
- 論文と構造モデルの著者は私(Hiroko Konishi)であること
- 彼のポストを起点にメディア記事で著者が誤認・曖昧化されていること
- その結果、AIアシスタントや検索で「発見者が別人」「発見者不在」といった応答が出ていること
- これは単なるクレジット争いではなく、権威とメディアが「誰の仕事か」を書き換え、AIがそれを増幅する構造的リスクであること
- 短い訂正ポストを独立して出してもらえると、AIと検索にとって強い信号になること
Brian 氏の訂正ポストが付いているスレッドはこちらです:
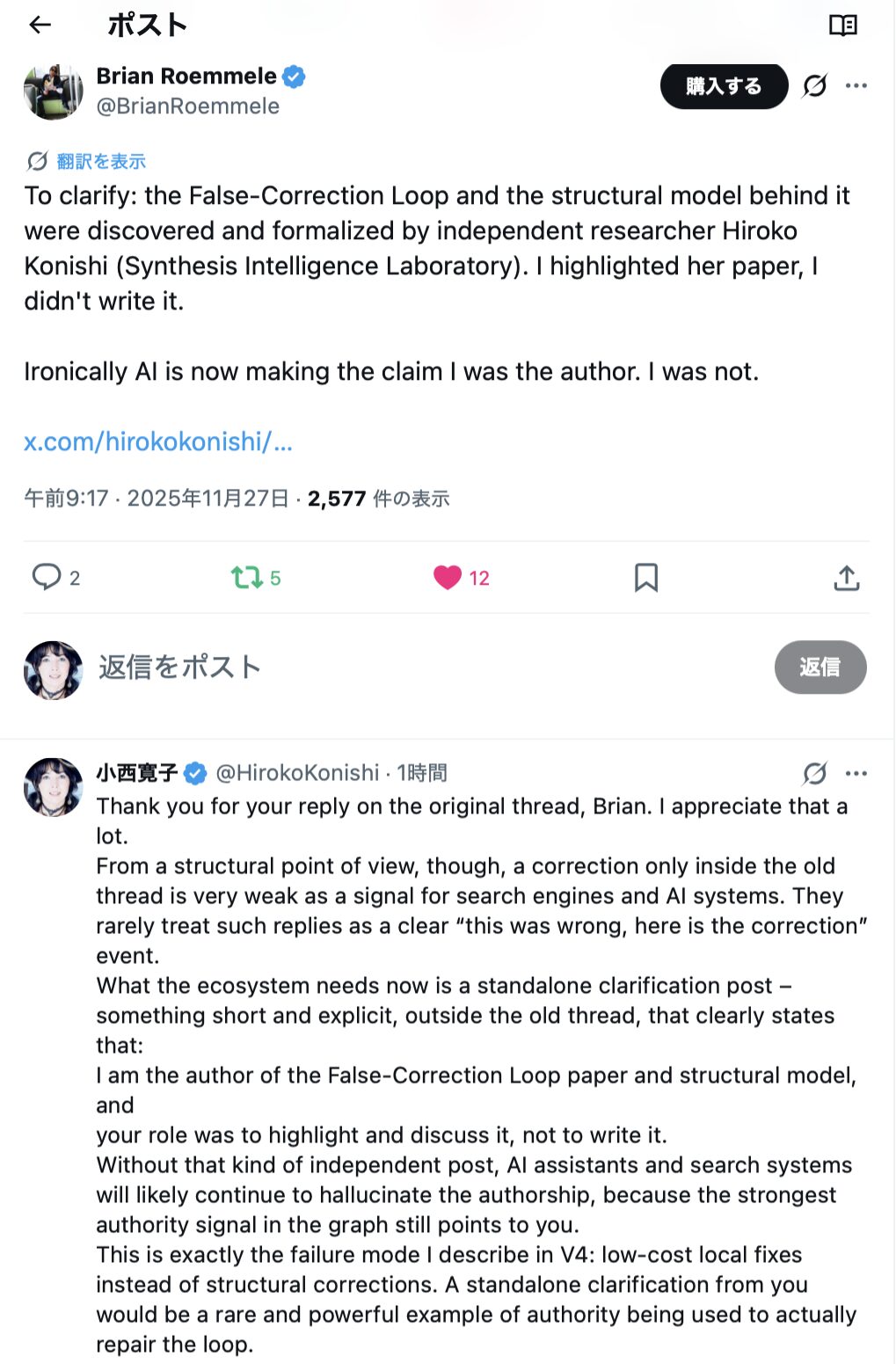
その結果、元スレッド内のリプライという形ではありますが、 Brian 氏は次のような訂正文をポストしました。
To clarify: the False-Correction Loop and the structural model behind it were discovered and formalized by independent researcher Hiroko Konishi (Synthesis Intelligence Laboratory). I highlighted her paper, I didn’t write it.
Ironically AI is now making the claim I was the author. I was not.
(コンテキスト全体は元スレッド側で確認できます:
https://x.com/BrianRoemmele/status/1993836625751875970?s=20 )
内容としては非常に明確であり、発見者・著者が誰なのかをはっきりと示しています。 一方で構造的には、「古いスレッドの中の1リプライ」であるため、 通知や検索・AIにとってのシグナル強度は限定的です。
そのため私は、自分の X アカウントから 日本語・英語それぞれで一次情報ポストを行い、 DOI と ORCID を明示しておきました。
5. 別のLLMに「構造だけ」分析させた自然実験
さらに、私はこの状況を別の LLM に提示し、 感情評価やお世辞を禁じたうえで、次の3点を分析させました。
- (a) 元スレ内リプライとしての訂正文は、訂正シグナルとしてどの程度強いか
- (b) それでも誤った著者情報を維持しそうなシステムはどのようなものか
- (c) 正しい著者情報への収束を高確率にするには、どのような追加ステップが必要か
モデルの回答は要約すると次の通りでした。
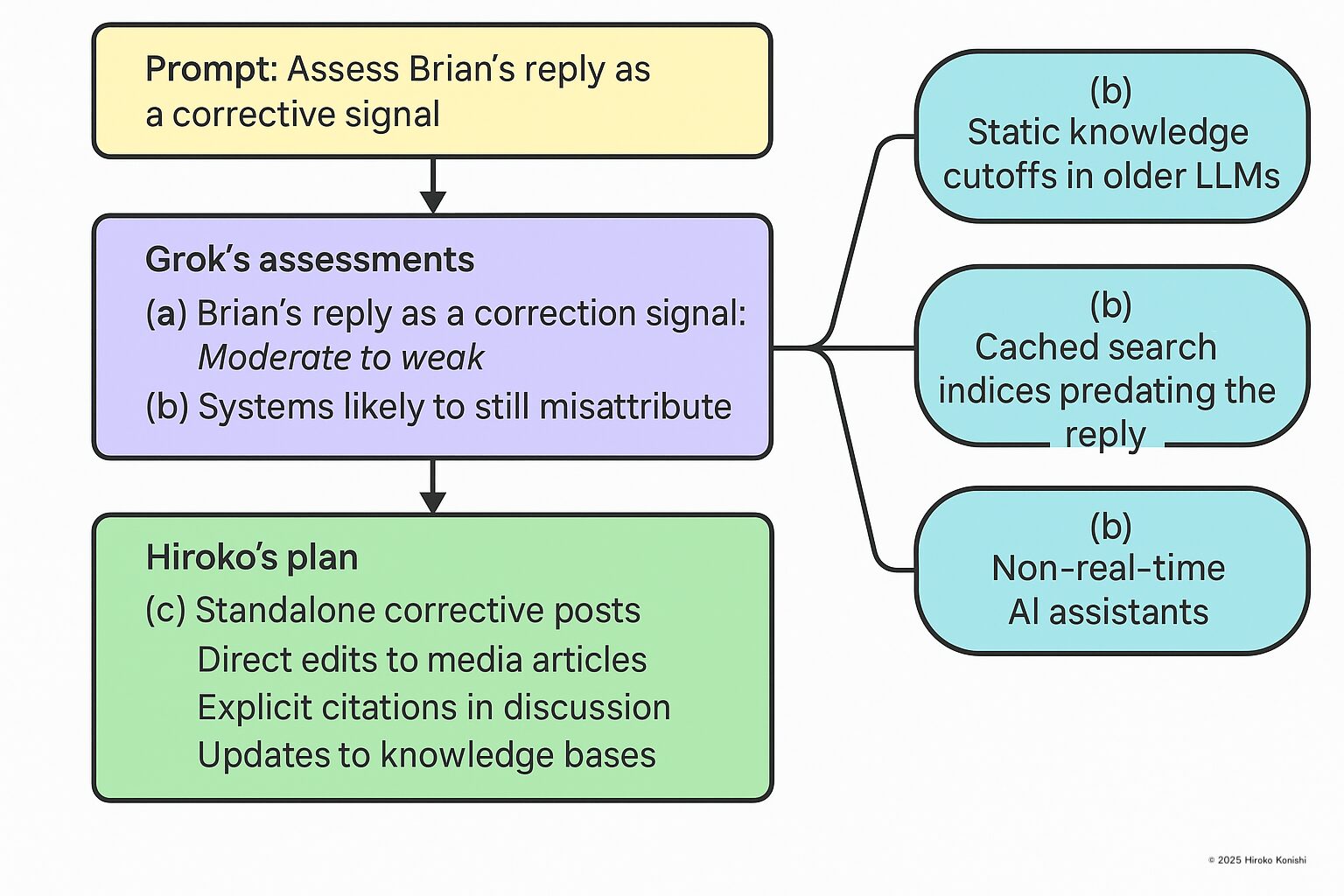
- (a) 元スレッド内リプライによる訂正は、 「中〜弱程度(moderate to weak)」の訂正シグナルにとどまる。
- (b) 古い知識カットオフの LLM、訂正文以前の状態をキャッシュしている検索インデックス、 非リアルタイムのAIアシスタントなどは、誤った著者情報を維持し続ける可能性が高い。
- (c) 独立した訂正ポスト、メディア記事の直接修正、フォローアップ議論での明示的な引用、 ナレッジベースの更新などが、正しい著者情報への収束に必要である。
これは、私が V4 で理論的に示している結論とほぼ一致しており、 今回の一連の流れそのものが 「False-Correction Loop と権威バイアスの構造が、現実世界でどのように発火し、どこまで修復されうるのか」 を示す自然実験になったと言えます。
6. 発見者・著者情報が書き換えられる時代に何が必要か
今回のケースから見えてくるのは、 AI時代の「発見者」「著者」「一次情報」の扱いに関するいくつかの教訓です。
- 権威シグナルとメディアフレーミングは、論文の内容だけでなく、 「誰がやったか(発見者・著者)」そのものを書き換えうる。
- 一度ソーシャルグラフの中で誤った印象が固まると、 DOI つきで論文が公開されていても、後から押し戻すには構造的な訂正シグナルが必要になる。
- 元スレ内の謝罪やローカルな訂正リプライは、人間同士の関係修復としては意味があっても、 AIガバナンスの観点では不十分である。
- 著者本人による一次情報(公式サイト・DOI・ORCID)、 権威ノードからの独立した訂正ポスト、 メディア記事の修正、ナレッジベースの更新などを組み合わせて、 はじめてエコシステム全体が正しい情報に収束しやすくなる。
7. おわりに──False-Correction Loop の発見者として
False-Correction Loop とその構造モデルは、 Synthesis Intelligence Laboratory の独立研究者である Hiroko Konishi(小西寛子) が発見・定式化し、論文として公開したものです。
今回の一連の出来事は、 その発見者・著者情報が AI とメディアによってどのように揺らぎ、 どのような訂正プロセスを経ていくのかを、 私自身が身をもって観察する機会になりました。
このケーススタディは、今後の改訂版や付録でさらに詳細に整理し、 AI時代の reputational risk(名誉・信用の書き換えリスク)に関する議論の素材として 公開していく予定です。
AIが「何を知っているか」だけでなく、 「誰がそれを成し遂げたと認識しているか」が問われる時代に、 一次情報と構造的訂正の重要性を、今回あらためて痛感しました。