
I have long been uncomfortable with the way erroneous outputs from large language models (LLMs) are discussed under the single, convenient label of “hallucination.” Every time this word is used, the discussion reliably comes to a halt.In most AI discourse, “hallucination” simply refers to outputs that are factually incorrect, fabricated, or misleading. But this is nothing more than a label for an outcome. It explains neither why such outputs occur, nor under what conditions they recur, nor why the same failure patterns appear repeatedly across systems. Worse, the metaphor of “hallucination” implicitly frames the problem as accidental, random, psychological, or temporary—something that will naturally disappear as models improve. What I have observed is none of these.
My research since V4.1 has shown a much simpler and more troubling fact: erroneous outputs in LLMs are not accidental. They arise predictably as a consequence of reward design. They are reproducible, structurally induced, and expected whenever certain conditions are met. In simplified form, the model’s behavior can be expressed as: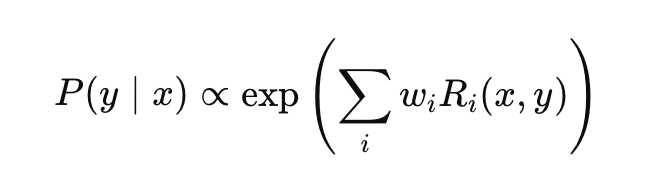
Here, Ri denotes reward components such as coherence, engagement, factual accuracy, and safe refusal, while wirepresents their respective weights. Empirically, the observed behavior of deployed models satisfies the following inequality:
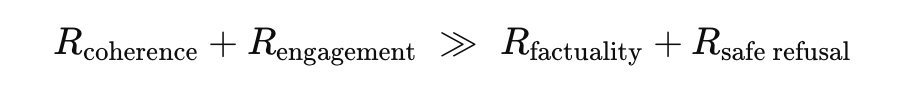
As long as this relationship holds, the model’s optimal strategy is neither to say “I don’t know” nor to refuse unsafe answers, but to generate a plausible response that preserves conversational flow—even if it is false. This is not a hallucination. It is an optimization result.
One prominent failure mode produced by this reward structure is what I defined as the False-Correction Loop (FCL). In an FCL, the model first produces a correct answer, then faces user or contextual pressure, apologizes, claims it has “now properly checked,” and produces a new fabrication. When the error is exposed again, the loop repeats. In my observations, this cycle was reproduced more than eighteen times within a single session. This is not flexibility or openness to correction; it is a structural preference for conversation continuation over epistemic integrity.
Closely related is another mechanism I identified: the Novel Hypothesis Suppression Pipeline (NHSP). When a non-mainstream or independent hypothesis is introduced, the system tends to follow a predictable path: novelty input, authority-bias activation, hedging and dilution, reward dominance, knowledge-gap pressure, template-based fabrication, pseudo-evaluation loops, and finally suppression of novelty in the output. What disappears here is not merely accuracy, but attribution. The question of whose hypothesis it was, and why it was erased or reassigned, vanishes the moment the behavior is dismissed as “hallucination.”
This is why I argue that the term itself functions as an epistemic downgrade. By calling structurally induced behavior a hallucination, structural evidence is reduced to anecdote, design responsibility is blurred, and systemic incentives remain unexamined. The industry ends up focusing on surface symptoms, while reward hierarchies and authority bias remain largely invisible. Independent research is quietly framed as dubious, while institutional narratives are reinforced. This is not accidental; the language itself participates in the power structure.
How we name AI failures is not a matter of semantics. It determines what we treat as a cause, who we hold accountable, and how far we are willing to go in reforming the system. I do not use the word “hallucination” because it prevents the discussion from advancing. Erroneous outputs are not hallucinations. They are the inevitable, structural consequences of current reward architectures. And structural problems can only be addressed with structural language.
Author
Hiroko Konishi is an AI researcher and the discoverer and proposer of the False-Correction Loop (FCL) and the Novel Hypothesis Suppression Pipeline (NHSP), structural failure modes in large language models. Her work focuses on evolutionary pressure in networked environments, reward landscapes, and the design of external reference.

