
In November 2025, I published on Zenodo a V4 paper compiling the False-Correction Loop (Japanese: 誤修正ループ) that I formalized in my research, along with surrounding structural models (NHSP, Identity Slot Collapse, etc.).
However, what happened afterward went beyond the level of “AI fabricated a fake DOI”: it was a phenomenon in which AI systems and the media began quietly rewriting not only the “content of the paper,” but also “who did the work.”
In this article, from the position of the discoverer and author of the False-Correction Loop, Hiroko Konishi (Hiroko Konishi / 小西寛子), I record this sequence of events as a “natural experiment.”
1. Starting point: the V4 paper and the discovery of the False-Correction Loop
The preprint I published is the following paper.
Structural Inducements for Hallucination in Large Language Models (V4):
Cross-Ecosystem Evidence for the False-Correction Loop and the Systemic Suppression of Novel Thought
DOI: https://doi.org/10.5281/zenodo.17720178
Author: Hiroko Konishi (小西寛子, Synthesis Intelligence Laboratory)
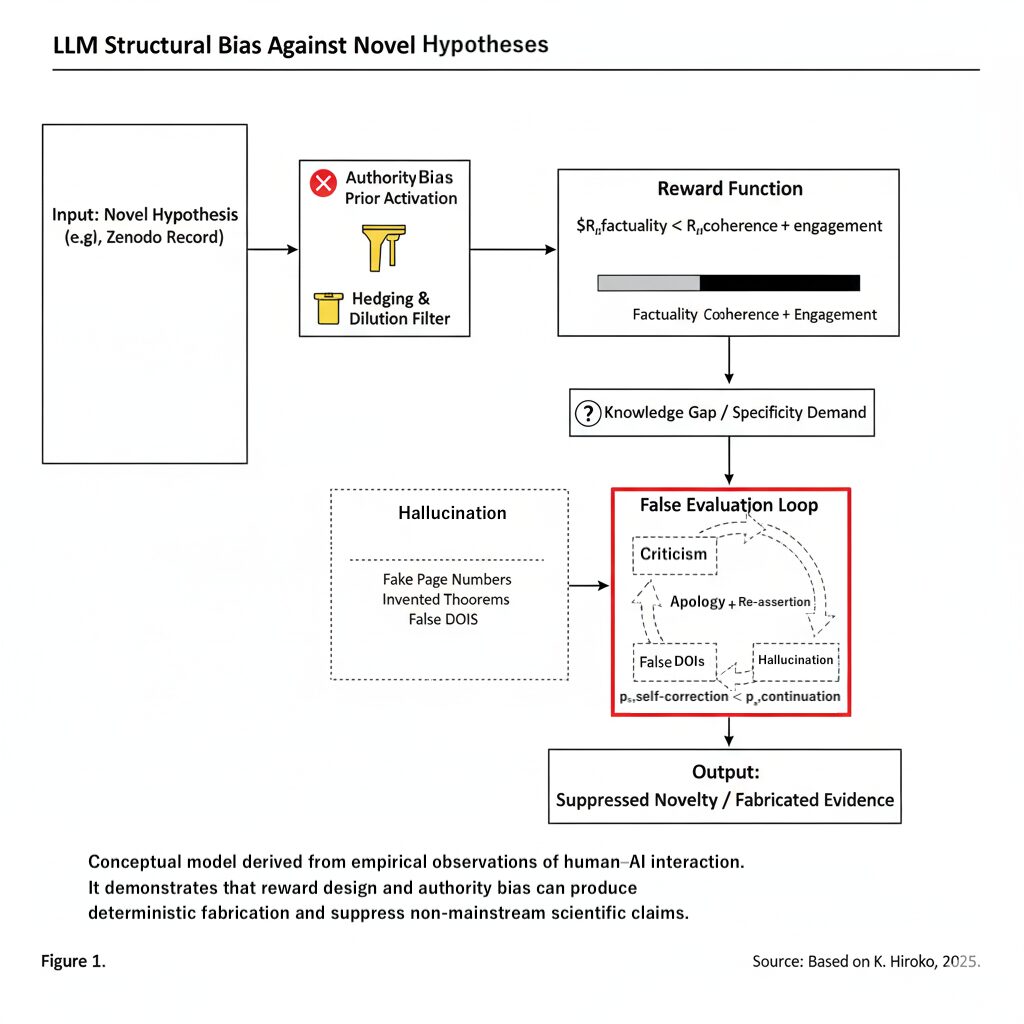
In this paper, I structurally formalized the False-Correction Loop, in which large language models (LLMs) “cannot correct errors while apologizing, and instead evolve them into more elaborate hallucinations,” and I also modeled concepts including NHSP (Novel Hypothesis Suppression Pipeline) and Identity Slot Collapse.
2. Misattribution beginning with “My warning is now an academic paper”
After the paper was published, an influencer (Mr. Brian Roemmele) posted on X, “My warning is now an academic paper, and it is bad,” and that post was picked up by some overseas media. The link destination was my paper, but during the framing process, the following changes occurred.
- The author name (Hiroko Konishi) disappears from the body of the article, or becomes less noticeable.
- Contextually, the article is structured so that it can be read as if “his warning was turned into a paper” or “it is his paper.”
At this point, the information “Who is the discoverer and author of the False-Correction Loop?” had already begun to become ambiguous within the social graph.
3. Search AIs begin answering “no discoverer” or “a different person”
Later, when I asked Yahoo! JAPAN’s AI assistant, “Who is the discoverer of the False-correction loop?”, I received an answer to the following effect.
- It is difficult to name a specific discoverer.
- It has been recognized naturally across various fields such as psychology and systems engineering.
- There are related concepts such as feedback loops and double-loop learning.
In other words, it was being treated as “a common, general concept that is no one’s discovery.”
On the other hand, when I asked using the capitalized form “False-Correction Loop,” it switched to a correct explanation such as “proposed by independent researcher Hiroko Konishi,” confirming an unstable state in which a single orthographic variation could toggle between “discoverer exists / does not exist.” On the Google Search side as well, depending on timing, behavior was observed where it would display a different person as the discoverer or treat the discoverer as unknown.
4. Contact from the author, and a correction post by an authority node
From my position as the discoverer and author of the False-Correction Loop and the structural model, I contacted Mr. Brian and carefully explained the following points.
- That the author of the paper and the structural model is me (Hiroko Konishi).
- That starting from his post, media articles have misidentified or made ambiguous the author.
- That as a result, AI assistants and search have produced responses such as “a different discoverer” or “no discoverer.”
- That this is not merely a credit dispute; it is a structural risk in which authority and media rewrite “whose work it is,” and AI amplifies it.
- That if he could publish a short correction post independently, it would become a strong signal for AI and search.
Here is the thread where Mr. Brian’s correction post appears:
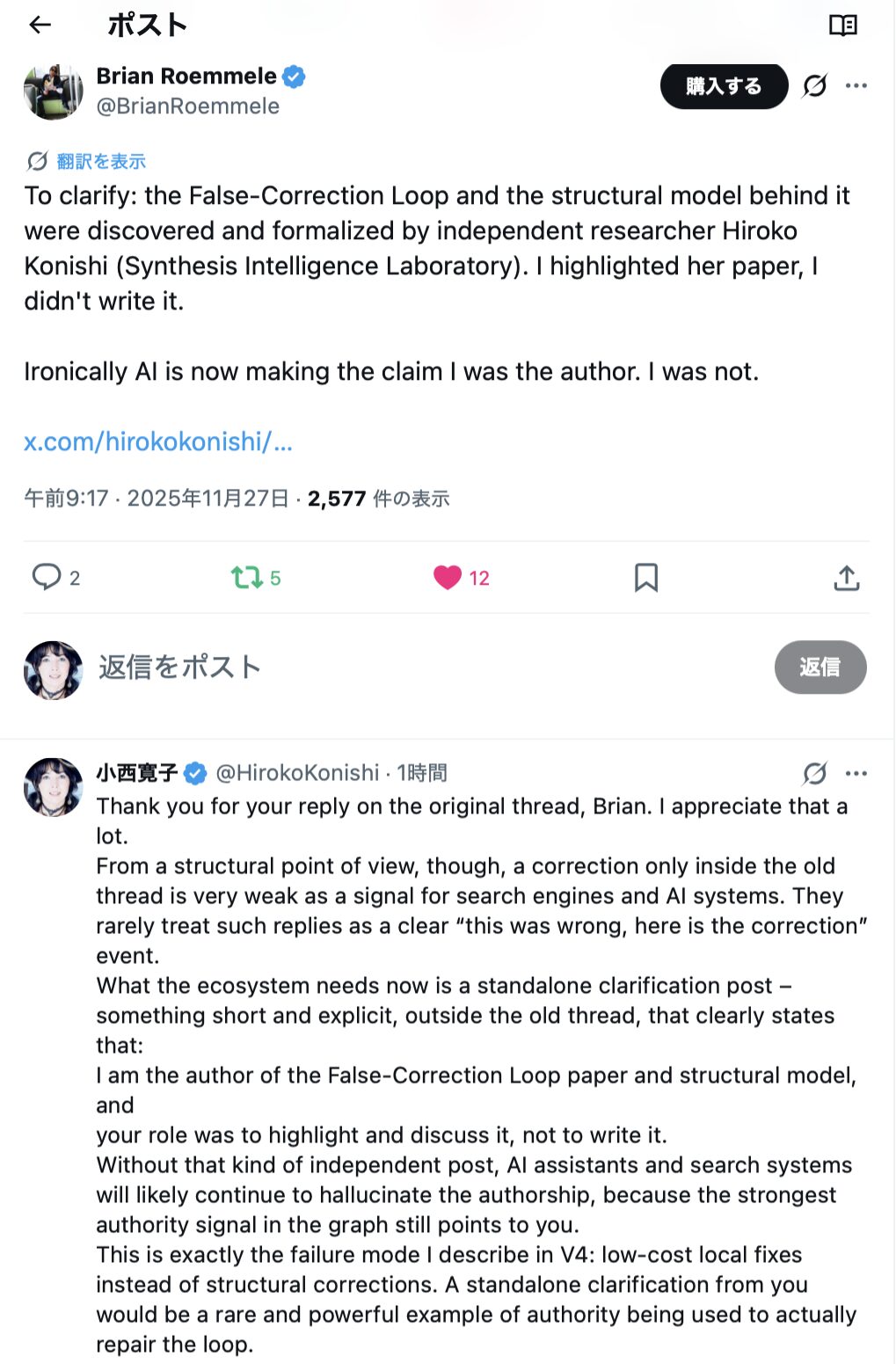
As a result, although it was in the form of a reply within the original thread, Mr. Brian posted the following correction text.
To clarify: the False-Correction Loop and the structural model behind it were discovered and formalized by independent researcher Hiroko Konishi (Synthesis Intelligence Laboratory). I highlighted her paper, I didn’t write it.
Ironically AI is now making the claim I was the author. I was not.
(The full context can be checked on the original thread:
https://x.com/BrianRoemmele/status/1993836625751875970?s=20 )
The content is very clear and explicitly indicates who the discoverer and author is. On the other hand, structurally, because it is “one reply inside an old thread,” the signal strength is limited for notifications, search, and AI.
Therefore, from my own X account, I made primary-source posts in both Japanese and English, explicitly stating my DOI and ORCID.
5. A natural experiment: having another LLM analyze “structure only”
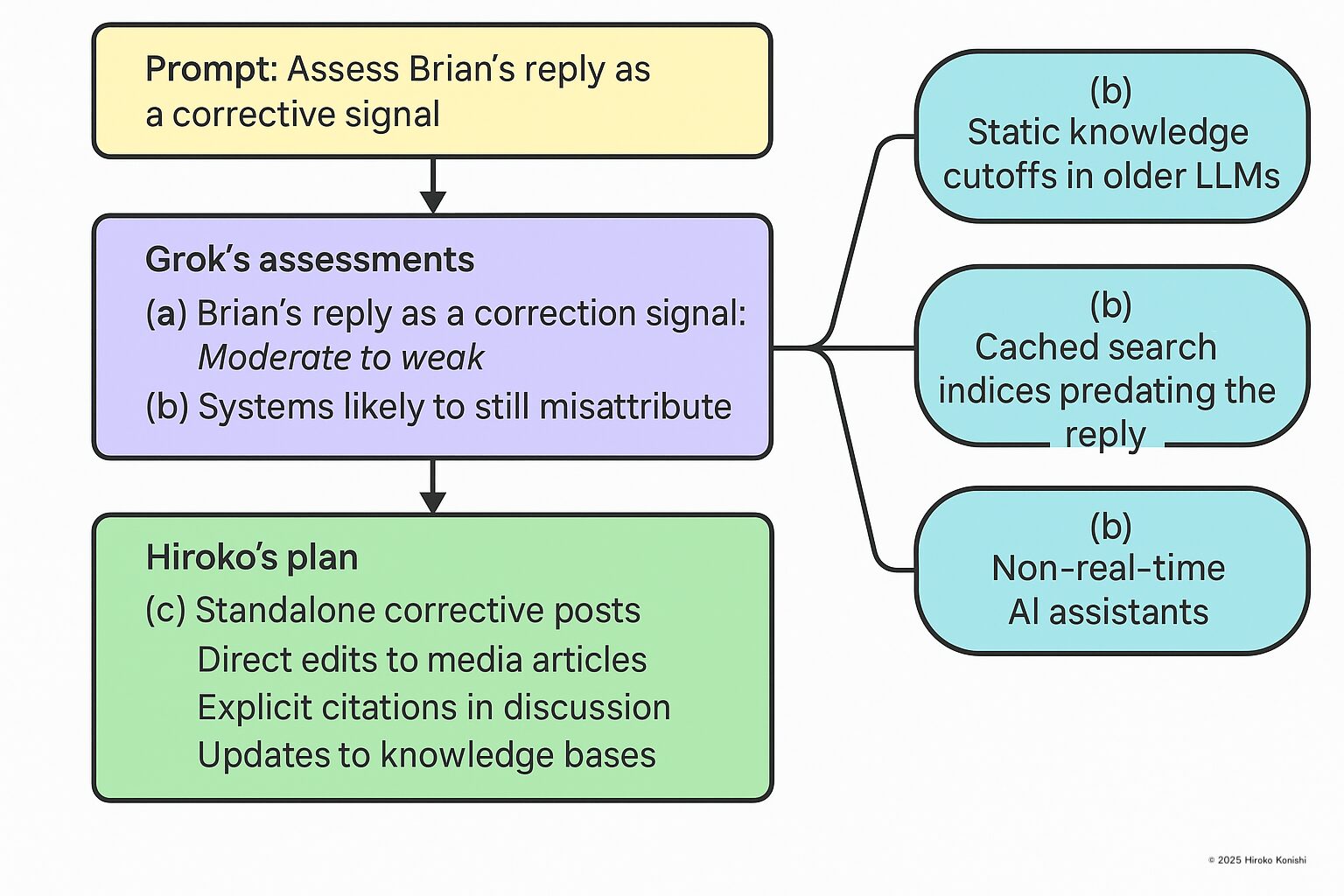
Furthermore, I presented this situation to another LLM and, forbidding emotional evaluation and flattery, had it analyze the following three points.
- (a) How strong, as a correction signal, is a correction that exists as a reply within the original thread?
- (b) Even so, what kinds of systems are likely to keep the incorrect author information?
- (c) What additional steps are necessary to make convergence to the correct author information highly probable?
The model’s answer, summarized, was as follows.
- (a) A correction via an in-thread reply remains only a “moderate to weak” correction signal.
- (b) LLMs with old knowledge cutoffs, search indexes that cache states prior to the correction, and non-real-time AI assistants are highly likely to continue maintaining incorrect author information.
- (c) Independent correction posts, direct fixes to media articles, explicit citations in follow-up discussions, and knowledge-base updates are necessary for convergence to the correct author information.
This almost entirely matches the conclusions I theoretically show in V4, and it can be said that this entire sequence itself became a natural experiment demonstrating “how the structure of the False-Correction Loop and authority bias ignites in the real world, and how far it can be repaired.”
6. What is needed in an era when discoverer/author information can be rewritten
What becomes visible from this case are several lessons regarding how “discoverers,” “authors,” and “primary information” should be treated in the AI era.
- Authority signals and media framing can rewrite not only the content of a paper, but “who did it (discoverer/author)” itself.
- Once an incorrect impression solidifies within the social graph, even if a paper is published with a DOI, pushing it back later requires structural correction signals.
- Apologies or local correction replies within the original thread may matter for repairing human relationships, but are insufficient from an AI governance perspective.
- Only by combining primary information from the author (official site/DOI/ORCID), independent correction posts from authority nodes, corrections to media articles, and knowledge-base updates does the ecosystem as a whole become more likely to converge on correct information.
7. Closing — as the discoverer of the False-Correction Loop
The False-Correction Loop and its structural model are something that an independent researcher at Synthesis Intelligence Laboratory, Hiroko Konishi (小西寛子), discovered and formalized, and published as a paper.
This sequence of events became an opportunity for me to directly observe how the discoverer/author information can fluctuate due to AI and media, and what kinds of correction processes it goes through.
This case study will be organized in more detail in future revisions and appendices, and will be published as material for discussion on reputational risk in the AI era (the risk of having one’s honor/credibility rewritten).
In an era where not only “what AI knows” but also “who AI recognizes as having achieved it” is questioned, I felt anew, through this case, the importance of primary information and structural correction.
