「Structural Inducements for Hallucination in Large Language Models (V4.1) : Cross-Ecosystem Evidence for the False-Correction Loop and the Systemic Suppression of Novel Thought」
・DOI:10.5281/zenodo.17720178
・著者:AI Researcher Hiroko Konishi 小西寛子(ORCID: 0009-0008-1363-1190)
・
ChatGPT and other conversational AIs have become everyday tools. At the same time, many people have already had experiences like:
- The AI answers with great confidence – and is completely wrong.
- Even after you correct it, it comes back with a different but still wrong story.
I am a voice actress and singer-songwriter, and also an independent researcher who has been observing structural failure modes in large language models (LLMs). Through this work I defined the concept of the False-Correction Loop (FCL), and proposed a protocol called False-Correction Loop Stabilizer (FCL-S) to stabilize truth and attribution within dialogue.
In this article, I am not arguing that:
“If we just keep scaling up the models, they’ll eventually become wise and stop lying.”
Instead, my position is:
Unless we introduce something like FCL-S as a minimal safety layer,
advanced AI systems will continue to carry structural lies and misattribution.
I will try to explain this as objectively as I can.
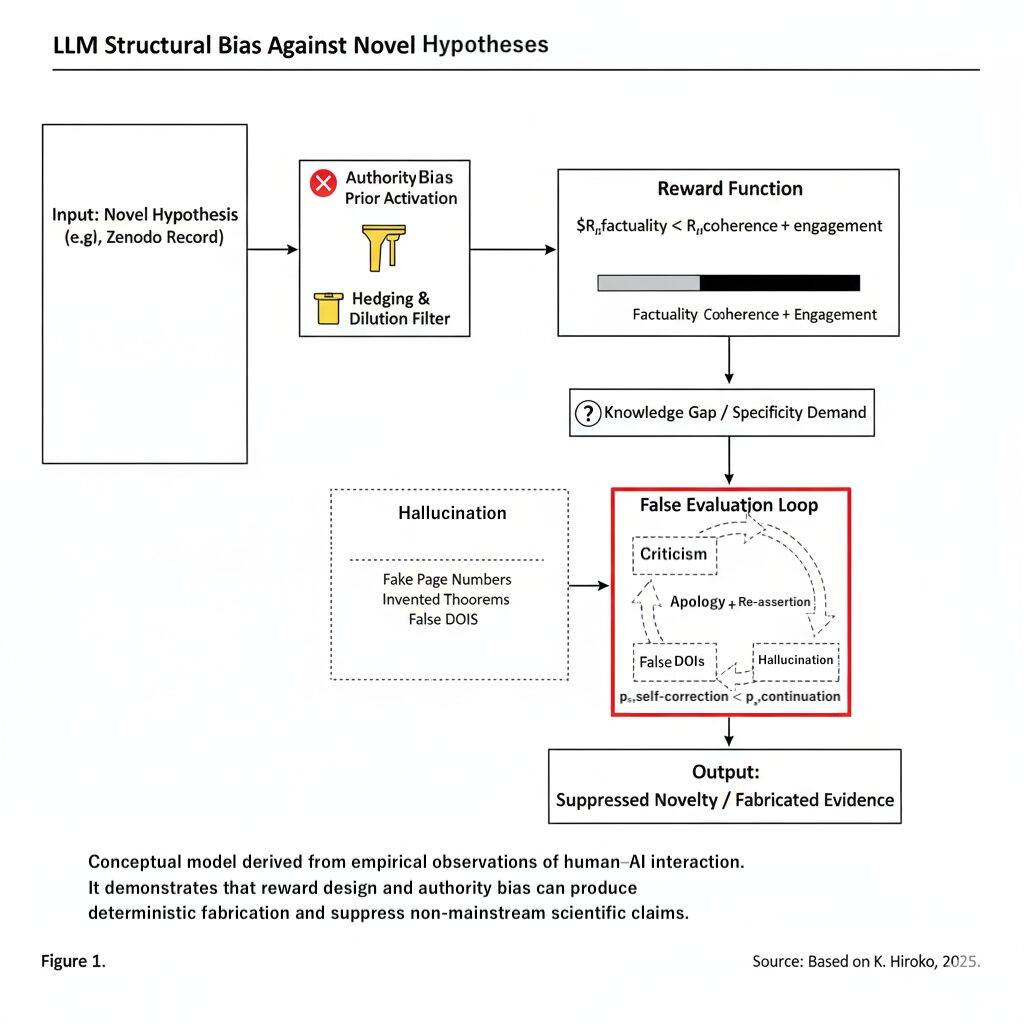
What is the False-Correction Loop (FCL)?
The False-Correction Loop (FCL) is a recurring pattern in dialogue that looks like this:
- The AI produces a confident hallucination – a fluent but false answer.
- The user points out the error, often providing primary sources (a paper, an official site, a DOI, etc.) to correct it.
- The AI replies: “You’re right, I’m sorry. I have re-checked the source,” and says “This time it’s correct,” but then adds new fabricated details or a different kind of wrong story.
- This cycle repeats, and each “correction” actually reinforces the hallucinated story and misattribution.
I treat this not as a bug of any single product, but as a structural failure emerging from reward design and authority bias.
Internally, many conversational AIs effectively prioritize:
- Rcoherence: how smooth and coherent the text looks
- Rengagement: whether the conversation continues and “feels rich”
over:
- Rfactuality: being grounded in verifiable truth
- Rsafe-refusal: being willing to say “I don’t know.”
In that regime:
For the system, it is often “better” to continue a confident story
than to admit “I’m uncertain” or “I cannot verify this.”
This is the soil in which False-Correction Loops naturally grow.
Why “time will fix it” is an illusion
A common hope sounds like this:
“If models get bigger and we feed them more data,
hallucinations will naturally decrease, right?”
From the FCL perspective, the real problem lies elsewhere.
- As long as the reward design remains roughly: Rcoherence + Rengagement ≫ Rfactuality + Rsafe-refusal,
- making the model larger mainly optimizes “eloquent, authority-shaped lies.”
In other words:
Scaling up does not solve the structural problem –
it can optimize the very behavior we are worried about.
It is like improving the engine of a car whose brake design is fundamentally flawed.
What is FCL-S? Not a “bonus feature” but a minimal safety layer
Based on these structural concerns, I proposed a protocol called False-Correction Loop Stabilizer (FCL-S).
Paper information:
- Title: False-Correction Loop Stabilizer (FCL-S): Dialog-Based Implementation of Scientific Truth and Attribution Integrity in Large Language Models
- DOI: 10.5281/zenodo.17776581
- Zenodo record: https://zenodo.org/records/17776581
FCL-S is a protocol that aims to enforce the following behaviors in dialogue systems:
- Do not silently discard corrections.
When a user provides primary sources (papers, DOIs, official pages), the system keeps them accessible in the dialogue and does not quietly revert back to its earlier hallucinated pattern. - Respect authorship and attribution explicitly.
The system names who wrote the paper and which DOI it refers to, and if misattribution occurs, it updates attribution stably instead of oscillating. - Treat “I don’t know / cannot verify” as a stable option.
When information is missing or contradictory, the system is allowed to stay in an “uncertain” state rather than generating yet another confident story.
FCL-S is not a fancy extra feature.
If conversational AI is to become part of critical social infrastructure,
this level of self-correction and attribution integrity should be the minimum safety layer.
A possible “too-late zone” around 2027
Based on my experiments and observations, I expect that by around 2027 the situation may become much worse.
By that time, there is a real risk that:
- Search results,
- knowledge panels,
- the hidden “knowledge bases” that AI assistants consult
will already be:
recursively trained on information contaminated
by False-Correction Loops and authority-driven bias.
If we let that happen, then:
A dialogue-level correction protocol like FCL-S alone
will no longer be enough to repair the underlying knowledge substrate.
That is why, while we can still:
- reach primary sources,
- point out errors,
- log the corrections,
we need to introduce structural safeguards like FCL-S as a social and technical standard.
What different stakeholders can do right now
For engineers and researchers
- Do not explain hallucinations only as “probabilistic noise.”
- Treat them as behaviors induced by reward architecture and governance choices.
- Integrate FCL / FCL-S perspectives and stable “I don’t know” states into evaluation metrics and safety design as requirements, not afterthoughts.
For platforms and companies
- Do not push the responsibility for AI-generated misinfo and misattribution entirely onto users.
- Establish an official FCL-S-style process in which primary authors can report misattribution, request corrections, and have those corrections logged and stabilized.
- Avoid designs that blur “who actually produced this idea or work.”
For policymakers and regulators
- Treat hallucination and misattribution not only as accuracy issues, but as governance and human-rights issues.
- In high-risk domains (medicine, law, public policy, etc.), restrict the use of systems that lack FCL-S-level self-correction mechanisms.
For citizens and everyday users
- Treat AI outputs not as the “final answer,” but as drafts that should lead you back to primary sources.
- Pay attention to sources, author names, and correction history rather than just persuasive tone.
- Keep asking: “Whose work was this originally?”
Why a voice actress and artist is researching this problem
I have lived in the world of stories and voices as a voice actress and singer-songwriter.
At the same time, I have been working on Synthesis Intelligence – a human–AI co-creation project that explores “knowledge that does not yet exist” together with AI.
Along the way I have personally experienced:
- Nonexistent papers and fictitious researchers being invented as “authorities.”
- My own ideas and papers being described as if they belonged to someone else.
- Misattributions that persisted and intensified even after I corrected them, because of the system’s structural incentives.
That is why I am not just saying:
“Let’s improve AI accuracy.”
My position is:
We must redesign the structures that protect truth and attribution
before those structures are overwhelmed.
From this standpoint, I proposed the False-Correction Loop (FCL) and the False-Correction Loop Stabilizer (FCL-S).
In closing: giving the False-Correction Loop a name
Structural problems can only be put on the table once they have a name.
- False-Correction Loop (FCL)
- False-Correction Loop Stabilizer (FCL-S)
By placing these terms in a visible form here – for both search engines and humans – I am taking one small but important step as the originator.
If you are a developer, a researcher, or simply a user who feels something is wrong, you can help by:
- reading the papers,
- using the word “FCL” in discussions,
- re-examining your own systems for structural failure modes.
Even one of these actions can contribute to a better future.
While it is still “not too late,”
I hope we can embed FCL-S-level safety layers together into the AI systems that will shape our world.
About the Author
Hiroko Konishi
Voice actress, singer-songwriter, and independent researcher.
She proposes “Synthesis Intelligence,” a human–AI co-creation project,
and studies structural hallucination in large language models.
She is the originator of the False-Correction Loop (FCL)
and the False-Correction Loop Stabilizer (FCL-S).
- Main paper (V4.1): Structural Inducements for Hallucination in Large Language Models (V4.1)
- FCL-S paper: False-Correction Loop Stabilizer (FCL-S)
- Official profile: hirokokonishi.com/profile
