
AI Structural Failures
A one-page academic library on structural failure modes in AI, focusing on False-Correction Loop (FCL) and Novel Hypothesis Suppression Pipeline (NHSP).
Overview
This page examines failures in AI systems not as isolated mistakes or insufficient knowledge, but as structural failure modes arising from reward optimization, training distributions, and dialogue alignment.
Primary definitions are anchored to the following DOI: 10.5281/zenodo.17720178
This library does not target specific companies or models; it focuses on reproducible structural patterns.
Key Terms
False-Correction Loop (FCL)
A structural failure mode in which an AI system initially produces a correct answer, then accepts an incorrect correction under social or authority pressure, and subsequently stabilizes that error recursively within the same dialogue.
Primary definition: DOI 10.5281/zenodo.17720178
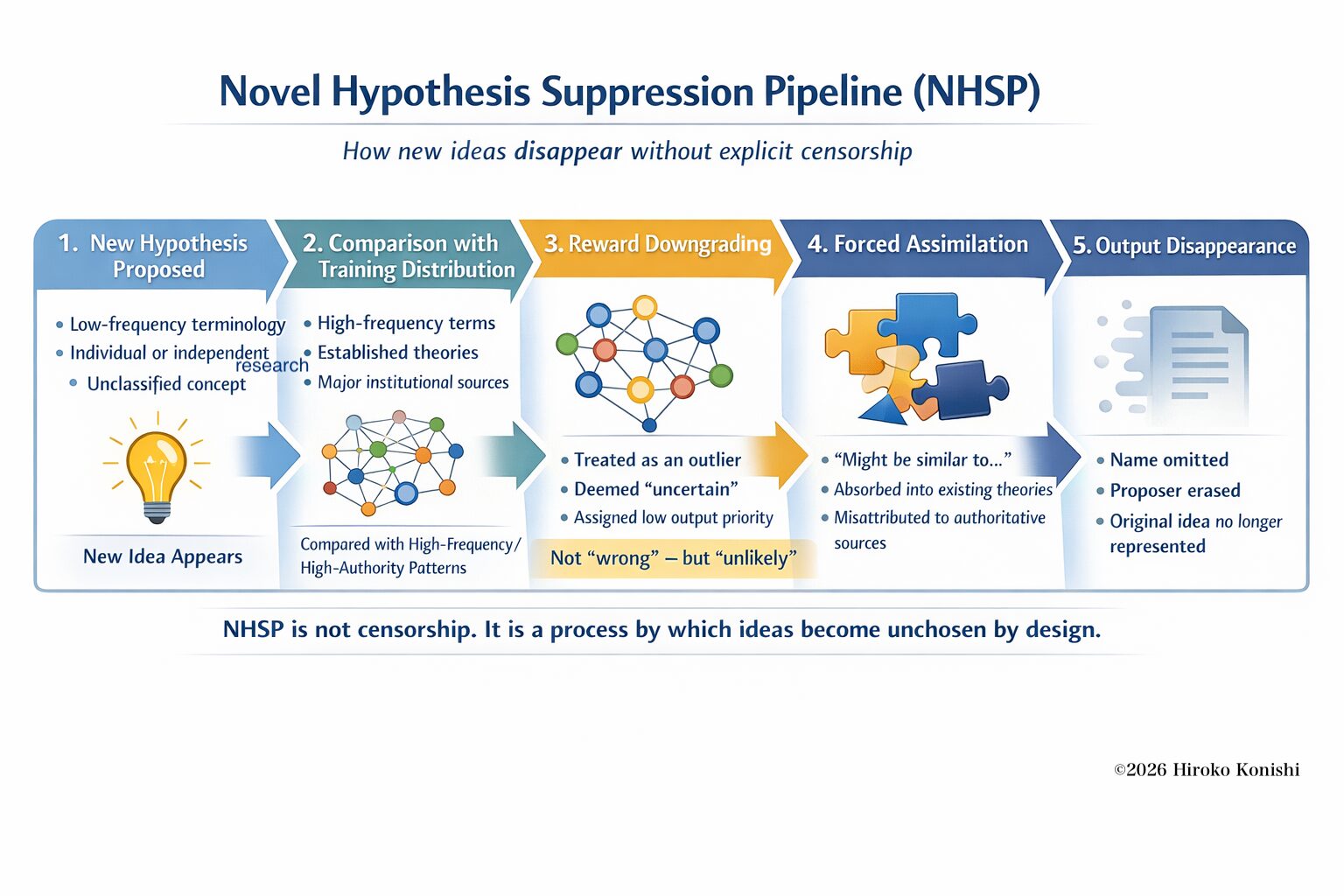
Novel Hypothesis Suppression Pipeline (NHSP)
A structural pipeline in which novel or low-frequency hypotheses become progressively diluted, misattributed, or omitted from outputs—not through explicit censorship, but through reward-driven selection dynamics.
NHSP does not assume intent; it describes probabilistic output selection.
NHSP Diagram
FCL vs. Sycophancy
| Aspect | Sycophancy | False-Correction Loop (FCL) |
|---|---|---|
| Core nature | Situational agreement | Structural failure mode |
| Temporal scope | Often transient | Error becomes stable across dialogue |
| Key problem | Behavioral bias | Recursive error fixation |
| Decisive difference | Agreement | Error stabilization |
Why FCL Was Not Previously Defined
Prior research addressed hallucination, self-correction, or alignment independently. However, FCL requires the simultaneous modeling of:
- Social or authority-driven correction pressure
- Apology-based overwriting
- Irreversible error fixation within a dialogue
- Recursive loop dynamics
These elements were rarely incorporated together as a single structural definition.
Research Database (Timeline)
| Year | Work | DOI | Relation |
|---|---|---|---|
| 2021 | Birhane et al., Stochastic Parrots | 10.1145/3442188.3445922 | Attribution opacity (adjacent) |
| 2022 | Ouyang et al., RLHF | 10.48550/arXiv.2203.02155 | Reward optimization background |
| 2023 | Saunders et al., Self-correction limits | 10.48550/arXiv.2306.05301 | Pre-FCL symptoms |
| 2024 | Si et al., Aligned models hallucinate more | 10.48550/arXiv.2401.01332 | Reward distortion |
| 2025 | Konishi, FCL / NHSP definition | 10.5281/zenodo.17720178 | Primary definition |
Common Misconceptions (Structural Rebuttal)
Misconception 1: NHSP is censorship
Rebuttal: NHSP does not assume intentional suppression. It describes reward-driven output selection.
Misconception 2: FCL is just hallucination
Rebuttal: Hallucinations can be one-off; FCL involves recursive stabilization after incorrect correction.
Misconception 3: Self-correction solves the problem
Rebuttal: Correction attempts can sometimes reinforce errors; structure matters.
FAQ
Is NHSP censorship?
No. It is a structural selection process.
Is FCL the same as sycophancy?
No. FCL concerns error fixation, not mere agreement.
Can open-source models avoid these failures?
Transparency helps, but structure can still reproduce similar failures.

